今天凌晨,微软在官网发布了AI Agent 5大可观测性最佳实践,以帮助开发者深度解决智能体盲跑、自动化流程不可控等难题。
智能体可观测性的主要好处包括:在开发早期检测并解决问题;验证智能体是否符合质量、安全和合规标准;优化生产中的性能和用户体验;维护智能体的信任和问责制等。
同时还展示了5个应用案例,让大家更直观地了解这项技术。

什么是智能体可观测性
简单来说,智能体可观测性就是对智能体从基础开发、测试、部署到后期维护运营全生命周的工作原理、决策、结果进行深度监测,帮助它们纠正各种错误实现更强、安全的自动化业务流程。主要有以下好处:
持续监控:实时跟踪智能体行为、决策和互动,以发现异常、意外行为或性能漂移。例如,企业客服AI智能体,正常情况下会优先回复未读消息,但监控时发现它突然频繁重复发送相同内容,或响应延迟从2秒飙升到10秒,系统会立即预警,提醒开发者排查问题。
追踪:捕获详细的执行流程,包括智能体如何推理任务、选择工具以及与其他智能体或服务协作。例如,电商订单处理AI智能体,用户下单后它需要调用库存系统、支付系统和物流系统。通过追踪就能看到,它先自动检查库存→调用支付接口→成功后通知物流,若订单失败,也能精准定位是某一步工具调用出错。

日志记录:记录智能体决策、工具调用和内部状态变化,以支持智能体式AI工作流程中的调试和行为分析。
例如:智能办公AI智能体,帮用户安排会议时,日志会记下10:00接收到“约周三3点会议”需求→调用日历工具查询参会人空闲时间→调整建议周三4点→最终用户确认。后续如果用户反馈没约上,可通过日志回看每一步操作找问题。
评估:系统性地评估智能体输出的质量、安全、合规性以及与用户意图的一致性,使用自动化和人工参与的方法。
例如,金融咨询AI智能体,用户问“如何规避股票风险”,自动化评估会检查它是否推荐了合规投资策略,人工再补充评估:回答是否贴合用户风险规避的核心需求,有没有遗漏关键提醒。
治理:执行政策和标准,以确保智能体以符合伦理、安全和组织及监管要求的方式运行。例如,教育领域AI智能体,根据治理规则,它必须过滤暴力教学方法歧视性内容,若有用户问“怎么惩罚不听话的学生”,智能体会拒绝回答并引导正确教育方式,避免违反教育行业伦理和监管要求。
微软提供智能体可观测性解决方案
微软的Azure AI Foundry可观测性是一个统一的解决方案,用于在Azure AI Foundry中端到端地评估、监控、追踪和治理智能体的质量、性能和安全性。所有这些都融入到你的智能体开发循环中。
从模型选择到实时调试,Foundry可观测性功能使团队能够自信且快速地推出生产级AI。
凭借内置的Agents Playground评估、Azure AI红队智能体和Azure Monitor集成等功能,Foundry可观测性将评估和安全性融入智能体生命周期的每一步。团队可以追踪每个智能体流程并获取完整的执行上下文,模拟对抗性场景,并使用可定制的仪表板监控实时流量。
无缝的CI/CD集成使得在每次提交时都能进行持续评估,而与Microsoft Purview、Credo AI和Saidot集成的治理支持有助于与欧盟AI法案等监管框架保持一致,使大规模构建负责任的、生产级AI更加容易。
深度了解:https://learn.microsoft.com/en-us/azure/ai-foundry/concepts/observability

5大智能体可观测性实践
1、利用基准驱动的排行榜选择合适的模型
每个智能体都需要一个模型,选择合适的模型是智能体成功的基础。在规划你的AI智能体时,你需要决定哪种模型最适合你的用例,就安全性、质量和成本而言。
你可以通过在自己的数据上评估模型,或者使用Azure AI Foundry的模型排行榜来比较基础模型,这些模型通过质量、成本和性能,由行业基准支持进行开箱即用的比较。
借助Foundry模型排行榜,你可以找到在各种选择标准和场景中的模型领导者,可视化标准之间的权衡,并深入查看详细指标,从而做出自信、数据驱动的决策。

安永全球微软联盟联合创新负责人、董事总经理-Mark Luquire表示,Azure AI Foundry的模型排行榜让我们有信心将客户解决方案从实验扩展到部署。并排比较模型帮助客户选择最适合的模型自信地平衡性能、安全性和成本。
2、在开发和生产中持续评估智能体
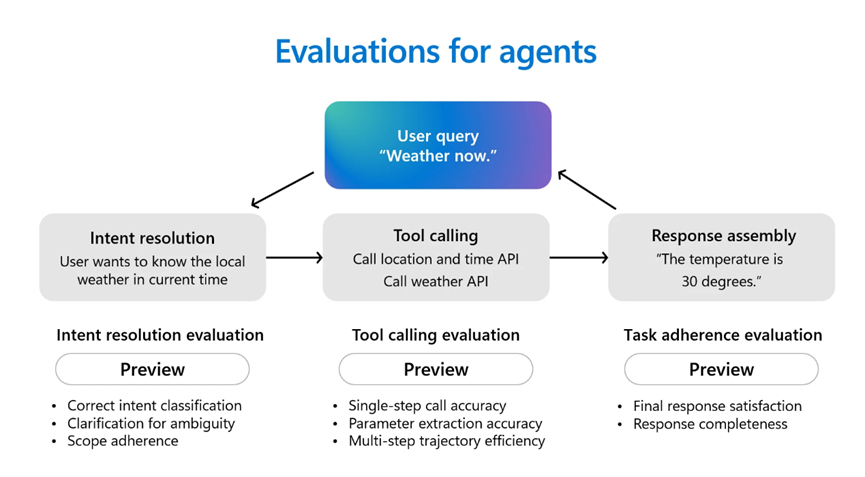
智能体是强大的生产力助手。它们可以规划、做决策并执行行动。智能体通常首先通过对话推理用户意图,选择正确的工具来调用并满足用户请求,并根据其指令完成各种任务。在部署智能体之前,评估其行为和性能至关重要。
Azure AI Foundry通过支持开箱即用的几种智能体评估器,使智能体评估变得更加容易,包括意图解析,智能体识别和解决用户意图的准确性;任务遵循,智能体完成已识别任务的情况;工具调用准确性,智能体选择和使用工具的有效性以及响应完整性,智能体的响应是否包含所有必要信息。
除了智能体评估器之外,Azure AI Foundry还提供了一整套评估器,用于更广泛地评估AI的质量、风险和安全性。这些包括质量维度,如相关性、连贯性和流畅性,以及全面的风险和安全性检查,评估代码漏洞、暴力、自残、性内容、仇恨、不公平性、间接攻击以及受保护材料的使用。
Azure AI Foundry Agents Playground将这些评估和追踪工具整合到一个地方,让你能够高效地测试、调试和改进智能体式AI。

Hughes Network Systems人工智能总监Amarender Singh表示,Azure AI Foundry中的稳健评估工具帮助我们的开发人员持续评估我们AI模型的性能和准确性,包括达到连贯性、流畅性和有根据的标准。
3、将评估集成到你的CI/CD流水线中
自动化评估应该是你的CI/CD流水线的一部分,以便在发布之前对每个代码更改进行质量和安全测试。这种方法有助于团队尽早发现回归,并有助于确保智能体在演变过程中保持可靠。
Azure AI Foundry使用GitHub Actions和Azure DevOps扩展与你的CI/CD工作流程集成,使你能够在每次提交时自动评估智能体,使用内置的质量、性能和安全性指标比较版本,并利用置信区间和显著性检验来支持决策——帮助确保你的智能体的每个迭代都已准备好投入生产。

Veeam高级软件工程师Justin Layne Hofer表示,我们已将Azure AI Foundry评估直接集成到我们的GitHub Actions工作流程中,因此我们AI智能体的每次代码更改在部署之前都会自动进行测试。这种设置帮助我们快速发现回归,并在我们迭代模型和功能时保持高质量。
4、在生产之前使用AI红队测试扫描漏洞
安全性和安全性是不容妥协的。在部署之前,通过模拟对抗性攻击主动测试智能体的安全性和安全风险。红队测试有助于发现可能在现实场景中被利用的漏洞,增强智能体的健壮性。
Azure AI Foundry的AI红队智能体自动化对抗性测试,测量风险并生成准备情况报告。它使团队能够模拟攻击并验证单个智能体响应和复杂工作流的生产准备情况。

埃森哲生成式AI首席架构师兼高级经理Nayanjyoti Paul表示,埃森哲已经在测试微软AI红队智能体,该智能体模拟对抗性提示并主动检测模型和应用的风险态势。
这个工具将有助于验证不仅单个智能体响应,还包括完整的多智能体工作流,其中级联逻辑可能会因单一对抗性用户而产生意外行为。红队测试让我们能够在这些情况进入生产之前模拟最坏的情况。这改变了游戏规则。
5、使用追踪、评估和警报在生产中监控智能体
部署后的持续监控对于实时发现问题是必不可少的,包括性能漂移或回归。使用评估、追踪和警报有助于维护智能体在其整个生命周期内的可靠性和合规性。
Azure AI Foundry可观测性通过由Azure Monitor Application Insights和Azure Workbooks提供支持的统一仪表板,实现持续的智能体式AI监控。
主要提供了对生产中智能体行为和性能的实时可见性,包括追踪、评估和警报。它使团队能够追踪每个智能体流程并获取完整的执行上下文,监控实时流量,识别异常行为,并设置警报以自动通知团队潜在问题。

Hughes Network Systems人工智能总监Amarender Singh表示,我们使用Azure AI Foundry可观测性来监控我们的生产智能体。它使我们能够追踪每个智能体流程并获取完整的执行上下文,监控实时流量,识别异常行为,并设置警报以自动通知团队潜在问题。这种可见性有助于我们快速响应并解决任何问题,确保我们的智能体始终可靠且安全。