






10月10日,由中科算网科技有限公司、算泥AI开发者社区联合主编,中国科学技术大学苏州高等研究院联合发布的《AI 大模型与异构算力融合技术白皮书》正式发布。白皮书精准聚焦当前大模型开发领域的核心痛点,致力于为开发者提供全面且实用的技术参考,助力推动大模型与异构算力实现深度融合。
以下为报告部分内容节选。
全球AI大模型发展概况
AI大模型与异构算力融合技术白皮书
国际大模型技术演进
2025年,全球AI大模型技术呈现出快速迭代、规模持续扩大、效率显著提升的发展趋势。以OpenAI的GPT系列为代表,从GPT-3的1750亿参数发展到GPT-4的预估1.7万亿参数规模,再到GPT-5可能达到3至50万亿参数,模型参数量呈指数级增长。Meta的Llama系列作为开源大模型的标杆,2025年4月发布的4.0版本首次采用MoE(Mixture of Experts)架构,提供了三个不同规模的版本:Llama 4 Scout(1090亿参数)、Llama 4 Maverick(4000亿总参数,170亿激活参数)和Llama 4 Behemoth(2万亿总参数,2880亿激活参数,16个专家),展现了大模型架构的创新方向。
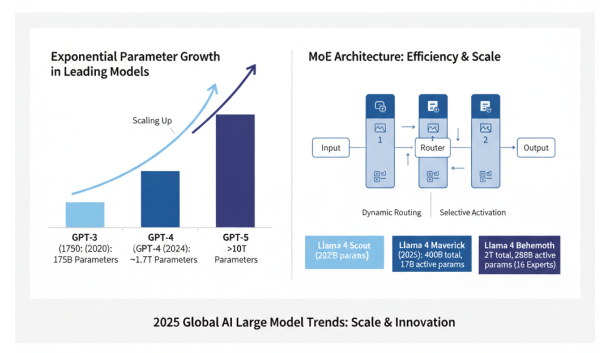
全球AI大模型参数规模的指数级增长与MoE架构的创新应用
在技术架构方面,Transformer已成为大模型的主流架构基础,同时各种创新变体不断涌现。MoE(混合专家模型)架构通过动态路由机制,在保持模型容量的同时显著降低了计算成本;世界模型(World Models)探索构建对环境的内部表征,为实现更通用的人工智能提供了新思路;多模态能力成为大模型的标配,从单一的文本处理扩展到图像、音频、视频等多种模态的理解和生成。2025年8月,Anthropic发布Claude Opus 4.1,将编码性能提升至SWE-bench Verified基准测试的74.5%,显著增强了深度研究和数据分析能力。

AI大模型技术架构的演进与开源生态的繁荣
开源生态的繁荣是国际大模型发展的另一重要特征。智谱的GLM系列、Meta的Llama系列、阿里的Qwen系列、腾讯混元系列、Mistral AI的Mistral系列、阿联酋的Falcon系列等开源模型的发布,极大地推动了大模型技术的普及和创新。这些开源模型不仅提供了强大的基础能力,还通过开放的权重和代码,为研究者和开发者提供了宝贵的实验平台,催生了大量基于开源模型的改进和应用。据Artificial Analysis公司2025年Q1报告显示,开源模型在性能上与闭源模型的差距正在缩小,在某些特定任务上甚至实现了超越。
国内大模型技术进展

中国大模型“提质增效”及主要参与者
中国在大模型领域的发展呈现出”提质增效”的态势,涌现出一批具有国际竞争力的模型和产品。阿里巴巴的通义千问(Qwen)系列在开源社区备受关注,通过持续迭代优化,在多模态理解和生成方面取得显著进展。华为的盘古大模型在千亿级参数基础上,进一步优化了训练效率和推理性能,覆盖NLP、科学计算等多个领域,并在华为的全栈AI生态中得到广泛应用。
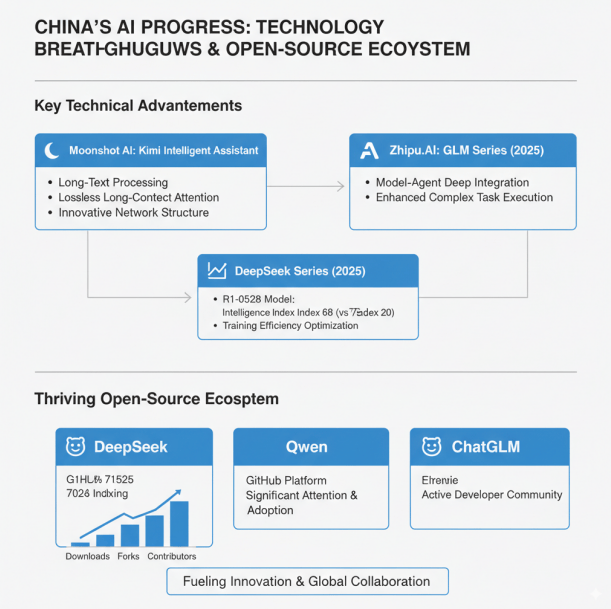
智谱AI的GLM系列和月之暗面的KIMI智能助手代表了国内大模型在特定技术路线上的突破。KIMI通过创新的网络结构和工程优化,在长文本处理方面形成了差异化优势,实现了无损的长程注意力机制。GLM系列则在2025年进一步融合了原生Agent能力,实现模型与Agent的深度融合,提升了复杂任务的执行能力。
2025年,DeepSeek系列模型在国内外引起广泛关注,其R1-0528模型智能指数已达到68,相较于最初的67B模型有了显著提升,展现了中国在大模型训练效率优化方面的实力。国内大模型在开源生态方面也取得了显著进展,Deepseek、Qwen、ChatGLM等开源模型在GitHub等平台获得了大量关注和应用,形成了活跃的开发者社区。
大模型应用场景拓展

大模型市场规模及应用生态概览
随着大模型技术的不断成熟,其应用场景也在不断拓展和深化。从最初的通用对话场景,逐步扩展到金融、医疗、工业等垂直行业,形成了丰富的应用生态。据艾媒咨询数据显示,2024年中国AI大模型市场规模约为294.16亿元,预计2026年将持续快速增长。
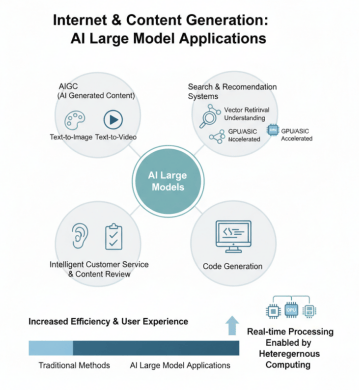
互联网与内容生成领域的大模型应用
在互联网与内容生成领域,AIGC(AI生成内容)应用蓬勃发展,包括文生图、文生视频等应用,异构算力的支持使得实时生成成为可能。大模型搜索与推荐系统通过向量检索、语义理解等技术,GPU/ASIC加速推荐系统推理,提升了用户体验和系统效率。智能客服、内容审核、代码生成等应用也在互联网企业中得到广泛应用,大幅提升了业务效率和用户体验。
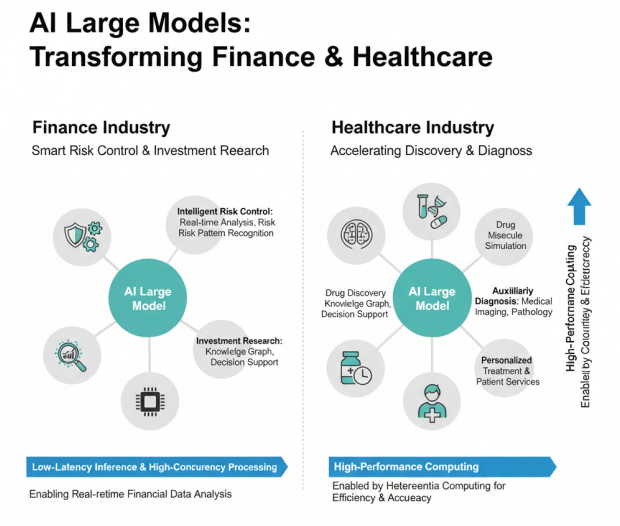
金融与医疗领域的大模型应用
在金融领域,大模型与知识图谱结合,在智能风控与投研方面发挥重要作用。低延迟推理、高并发处理能力使得大模型能够实时分析海量金融数据,识别风险模式,辅助投资决策。国产AI芯片在金融客户案例中表现出色,为金融行业的智能化转型提供了有力支撑。
在医疗领域,大模型应用场景迅速拓展,涵盖药物发现、辅助诊断、个性化治疗、医患服务等各个方面,展现出加快药物开发、早期发现疾病、提升诊疗效率的巨大潜力。医学影像分析、病理诊断、药物分子模拟等应用对算力要求极高,异构算力的引入显著提升了处理效率和准确性。
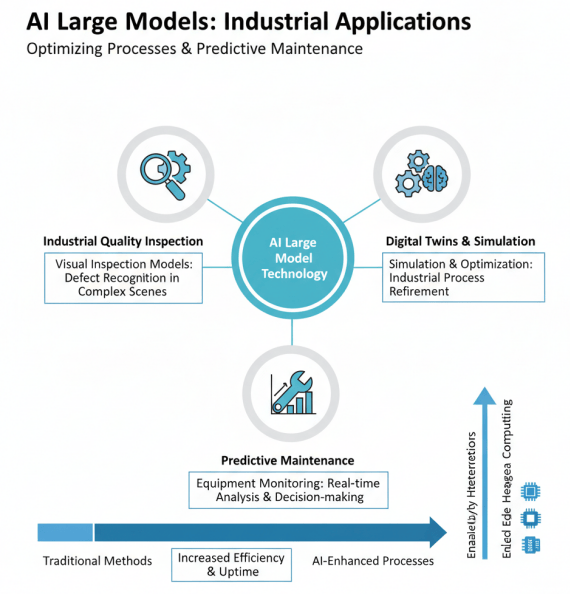
工业领域的大模型应用
在工业领域,大模型在工业质检、数字孪生、设备预测性维护等方面发挥重要作用。视觉质检大模型能够识别复杂工业场景中的缺陷,数字孪生技术通过大模型仿真优化工业流程,边缘异构算力的部署使得实时分析和决策成为可能。
算力需求爆发与挑战
AI大模型与异构算力融合技术白皮书
训练与推理算力需求分析
大模型训练对算力的需求呈现出前所未有的增长态势前沿模型的训练成本正以惊人的速度膨胀,Anthropic CEO预测训练成本可能在2027年达到100亿至1000亿美元级别。千亿参数模型训练一般需要上千张高性能GPU卡支撑,训练时间长达数月,对算力基础设施提出了极高要求。
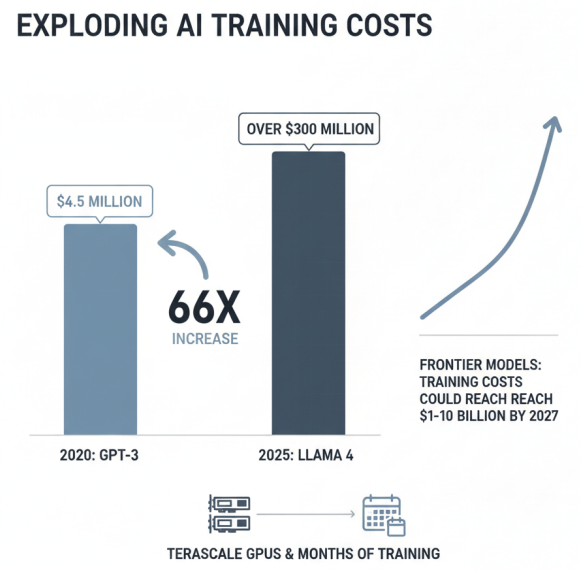
大模型训练成本的爆炸式增长
推理场景对算力的需求同样快速增长,但特点与训练有所不同。推理更注重低延迟、高并发和能效比。在实际应用中,大模型推理需要同时服务大量用户,对并发处理能力提出高要求;在实时交互场景,如智能客服、实时翻译等,对响应延迟极为敏感;在边缘设备和移动终端,对能耗和计算效率有严格限制。这些多样化的需求使得推理算力的优化和调度面临复杂挑战。
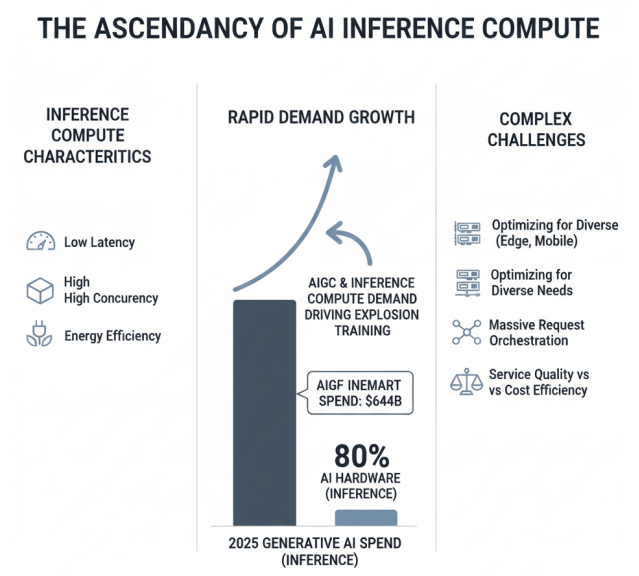
推理算力需求的特征、增长及其挑战
随着大模型应用的普及,推理算力的总需求已超过训练算力,成为算力消耗的主要部分。特别是在AIGC、智能助手等大规模应用场景,推理算力需求呈现爆发式增长。Gartner预测2025年生成式AI支出将达6440亿美元,其中约80%用于AI硬件,主要用于推理场景。如何高效满足海量推理请求,同时保证服务质量和成本效益,成为算力基础设施面临的重要课题。
算力墙、存储墙、通信墙
在大模型训练过程中,”三堵墙”——算力墙、存储墙和通信墙成为制约性能的主要瓶颈。
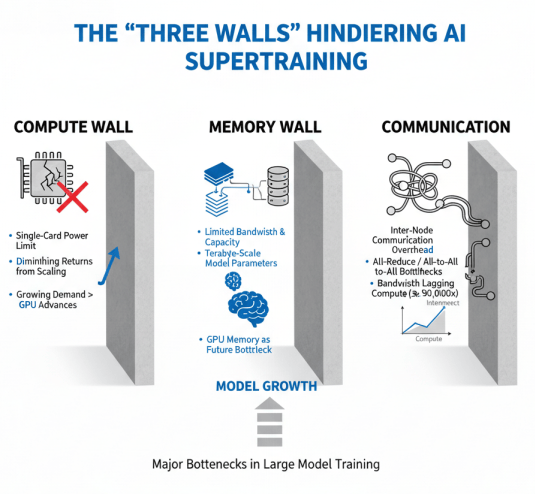
算力墙指的是单卡算力上限的限制,即使是最先进的GPU芯片,其计算能力也难以满足大模型训练的需求,必须通过大规模集群扩展算力。然而,随着模型规模的增长,单纯增加计算单元的效果递减,算力墙问题日益突出。
存储墙主要体现在内存带宽和容量的限制上。大模型参数量巨大,万亿参数模型需要数百GB到数TB的内存容量,而当前AI加速器的内存容量和带宽往往成为瓶颈。研究表明,AI训练未来的瓶颈可能不是算力,而是GPU内存,内存墙问题已成为制约大模型发展的关键因素。数据加载、参数交换等内存密集型操作往往成为训练过程中的性能瓶颈。
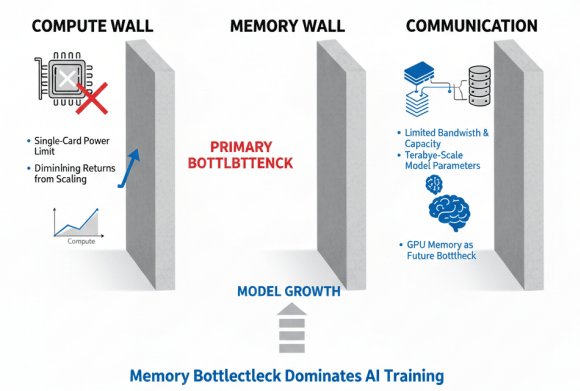
通信墙则是指集群网络通信开销的限制。大模型并行训练需要大量节点间通信,如AllReduce梯度同步、AlltoAll参数交换等,通信性能直接决定训练效率。无论是芯片内部、芯片间,还是AI加速器之间的通信,都已成为AI训练的瓶颈。扩展带宽的技术难题尚未被完全攻克,过去20年间,运算设备的算力提高了90,000倍,而互连带宽仅提高了30倍,通信墙问题日益严峻。
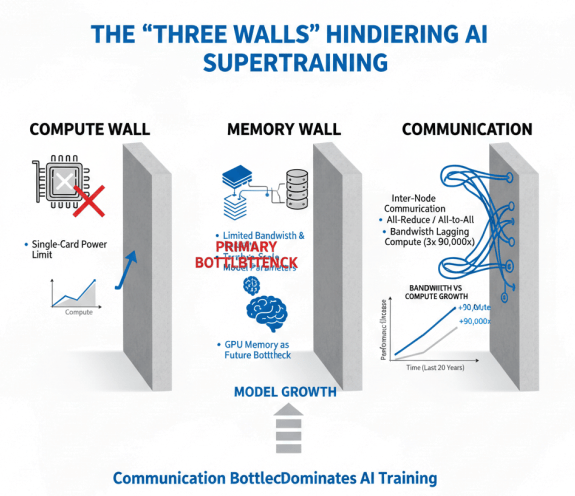
“通信墙”作为大模型训练的限制因素,对比算力与带宽增长的速度差异
算力成本与能效挑战
大模型训练和推理的高算力需求带来了巨大的成本压力。前沿模型的训练成本从2020年的450万美元增长到2025年的3亿美元以上,增长了约66倍。推理成本虽然相对较低,但随着应用规模的扩大,总体成本仍然可观。高昂的算力成本成为大模型技术普及和应用落地的重要障碍,特别是对于中小企业和科研机构而言。
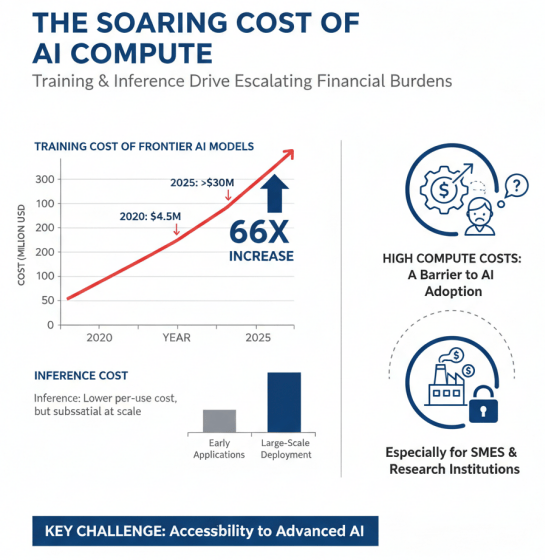
大模型训练和推理成本的快速增长,以及高算力需求带来的成本压力
数据中心能耗与”双碳”目标之间的矛盾日益凸显。算力需求呈指数级增长趋势,带来了数据中心能耗、成本以及碳排放的不断攀升。在”双碳”目标约束下,算电协同(算力与电力协同优化)正成为破解AI能耗困局、实现数据中心绿色可持续发展的关键路径。液冷技术作为降低数据中心能耗的重要手段,比传统电制冷节能20%-30%,正得到广泛应用。

数据中心能耗与“双碳”目标之间的矛盾,以及算电协同、液冷技术和能效比提升实现绿色算力的解决方案
能效比成为衡量算力基础设施的重要指标。传统的以性能为中心的设计理念正在向以能效为中心转变,绿色算力成为行业发展的重要趋势。液冷技术、可再生能源应用、算力调度优化等节能技术得到广泛应用,数据中心PUE(Power Usage Effectiveness)值不断降低。同时,芯片能效比(TOPS/W)的提升也成为AI芯片设计的重要目标,通过架构创新、制程工艺优化等手段,在提升算力的同时降低能耗。
异构算力成为主流趋势
AI大模型与异构算力融合技术白皮书
异构计算定义与分类
异构计算是指在同一计算系统集成不同类型或架构的处理单元,以便更有效地执行不同类型的任务。随着AI大模型对算力需求的多样化,单一架构的计算单元难以满足所有需求,异构计算通过组合不同特性的计算单元,实现整体性能的最优化。根据组合方式的不同,异构计算主要分为三类:CPU+GPU、CPU+FPGA和CPU+ASIC。
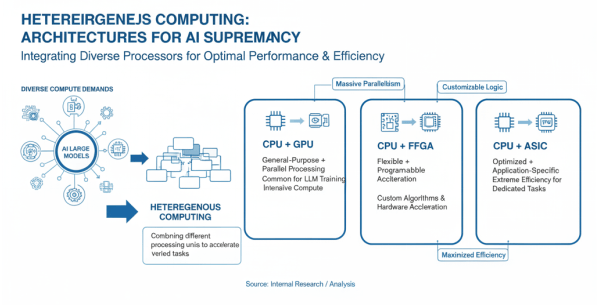
异构计算概述及其三大主要类型
CPU+GPU是最常见的异构计算组合,CPU负责通用计算和任务调度,GPU负责大规模并行计算。这种组合充分利用了GPU在并行计算方面的优势,适合大模型训练等计算密集型任务。CPU+FPGA组合则利用FPGA的灵活可编程特性,适合需要定制化加速的场景,如特定算法的硬件加速。CPU+ASIC组合则针对特定应用进行深度优化,如TPU(Tensor Processing Unit)专门用于加速TensorFlow计算,能效比极高。
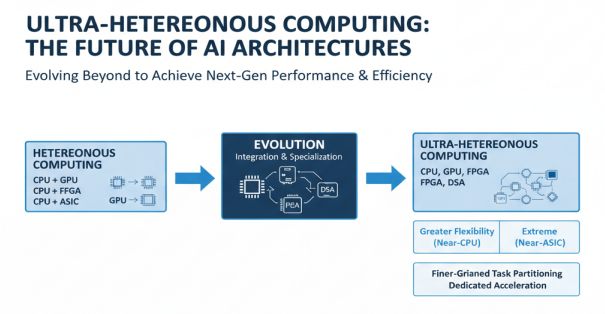
从异构计算到超异构计算的演进与优势
超异构计算是异构计算的进一步发展,由CPU、GPU、FPGA和DSA(Domain-Specific Architecture)多架构处理器组成,目标是接近CPU的灵活性和ASIC的性能效率。超异构计算架构通过更加精细的任务划分和专用加速,实现更高性能和能效,成为未来计算架构的重要发展方向。
异构算力在大模型场景优势
异构算力在大模型场景中展现出显著优势:
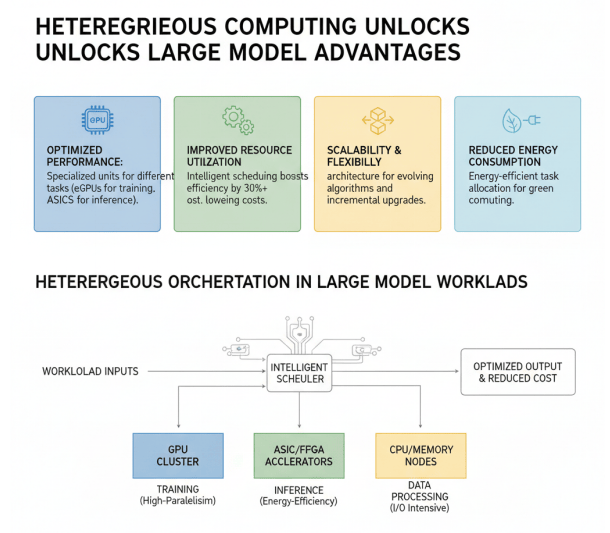
一、不同类型的计算单元擅长大模型不同环节,GPU在大规模并行计算方面表现优异,适合大模型训练;ASIC在特定任务上能效比极高,适合推理加速;FPGA则具有灵活可编程的特性,能够适应不断变化的算法需求。通过异构计算架构,可以将不同类型的计算任务分配给最适合的处理单元,从而实现整体性能的最优化。
二、异构调度能够显著提升资源利用率,降低总体成本。在实际应用中,大模型的工作负载往往呈现多样化特征,既有计算密集型的训练任务,也有延迟敏感型的推理任务,还有IO密集型的数据处理任务。异构算力通过智能调度,将不同类型的任务分配给最适合的计算资源,避免资源闲置和浪费,提高整体资源利用率。研究表明,合理的异构调度可以将资源利用率提升30%以上,显著降低算力成本。
三、异构算力提供了更好的扩展性和灵活性。随着大模型技术的快速发展,新的算法和模型结构不断涌现,对算力的需求也在不断变化。异构算力架构通过多种计算单元的组合,能够更好地适应这种变化,为新算法和新模型提供支持。同时,异构算力也支持渐进式的升级和扩展,企业可以根据需求逐步增加或更新计算资源,降低技术升级的成本和风险。
四、异构算力有助于降低能耗,实现绿色计算。不同类型的计算单元在能效比方面各有优势,通过异构调度,可以将任务分配给能效比最高的计算单元,从而降低整体能耗。特别是在推理场景,ASIC和FPGA等专用计算单元的能效比往往远高于通用计算单元,能够显著降低推理过程的能耗。在全球”双碳”目标下,异构算力的这一优势具有重要意义。
本报告共计分为“前言、AI大模型与算力行业现状、异构算力技术架构与核心组件、大模型与异构算力融合关键技术、国内企业实践与案例分析、行业应用与场景落地、挑战、趋势与展望”七大部分内容。上述文章仅为「AI大模型与算力行业现状」的部分内容摘选。
完整版报告,请扫描下方二维码或点击【阅读原文】下载。

END
